Scaling
This document describes how to manually and automatically scale Pods (Pulsar instances) that are used for running functions, sources, and sinks.
Manual scaling
In CRDs, the replicas parameter is used to specify the number of Pods (Pulsar instances) that are required for running Pulsar functions, sources, or sinks. You can set the number of Pods based on the CPU threshold. When the target CPU threshold is reached, you can scale the Pods manually through either of the two ways:
Use the
kubectl scale --replicascommand. The CLI command does not change thereplicasconfiguration in the CRD. If you use thekubectl apply -fcommand to re-submit the CRD file, the CLI configuration may be overwritten.kubectl scale --replicas="" pod/POD_NAMEUpdate the value of the
replicasparameter in the CRD and re-submit the CRD with thekubectl apply -fcommand.
Autoscaling
Autoscaling monitors your Pods and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost. With autoscaling, it is easy to set up Pods scaling for resources in minutes. The service provides a simple, powerful user interface that lets you build scaling plans for resources.
HPA
Kubernetes provides the Horizontal Pod Autoscaler (HPA) to automatically scale a workload resource (such as a Deployment or StatefulSet) as required.
Horizontal scaling increases loads by deploying more Pods.
How it works
With Kubernetes HPA, Function Mesh supports automatically scaling the number of Pods (Pulsar instances) that are required to run Pulsar functions, sources, and sinks.
For resources with HPA configured, the HPA controller monitors the resource's Pods to determine if it needs to change the number of Pod replicas. In most cases, where the controller takes the mean of a per-pod metric value, it calculates whether adding or removing replicas would move the current value closer to the target value.
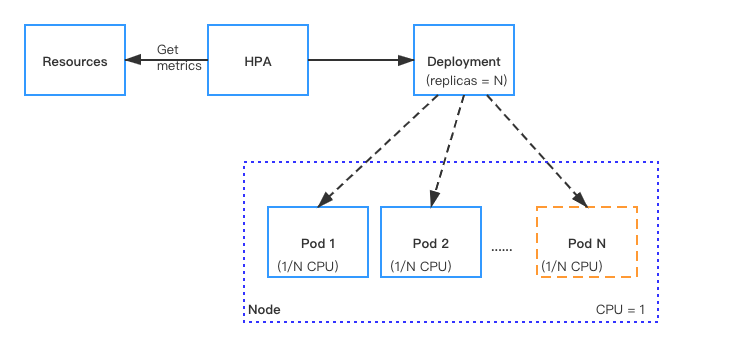
Supported HPA metrics
Function Mesh auto-scales the number of Pods based on the CPU usage, memory usage, and custom metrics.
Note
If you have configured HPA based on the CPU usage and/or memory usage, you do not need to configure HPA based on custom metrics defined in Pulsar Functions or connectors and vice versa.
CPU usage: auto-scale the number of Pods based on CPU utilization.
This table lists built-in CPU-based HPA metrics. If these metrics do not meet your requirements, you can auto-scale the number of Pods based on custom metrics defined in Pulsar Functions or connectors. For details, see MetricSpec v2 autoscaling.
Option Description AverageUtilizationCPUPercent80 Auto-scale the number of Pods if 80% CPU is used. AverageUtilizationCPUPercent50 Auto-scale the number of Pods if 50% CPU is used. AverageUtilizationCPUPercent20 Auto-scale the number of Pods if 20% CPU is used. Memory usage: auto-scale the number of Pods based on memory utilization.
This table lists built-in memory-based HPA metrics. If these metrics do not meet your requirements, you can auto-scale the number of Pods based on custom metrics defined in Pulsar Functions or connectors. For details, see MetricSpec v2 autoscaling.
Option Description AverageUtilizationMemoryPercent80 Auto-scale the number of Pods if 80% memory is used. AverageUtilizationMemoryPercent50 Auto-scale the number of Pods if 50% memory is used. AverageUtilizationMemoryPercent20 Auto-scale the number of Pods if 20% memory is used. Custom metrics: auto-scale the number of Pods based on custom metrics defined in Pulsar Functions or connectors. For details, see MetricSpec v2 autoscaling.
Examples
This section provides some examples about HPA.
Prerequisites
Deploy the Metrics server in the cluster. The Metrics server provides metrics through the Metrics API. The Horizontal Pod Autoscaler (HPA) uses this API to collect metrics. To learn how to deploy the metrics-server, see the Metrics server documentation.
Enable HPA
By default, HPA is disabled (the value of the maxReplicas parameter is set to 0). To enable HPA, you can specify the maxReplicas parameter and set a value for it in the CRD. This value should be greater than the value of the replicas parameter.
By default, when HPA is enabled, the number of Pods is automatically scaled when 80% CPU is used.
This example shows how to enable HPA by setting the value of the maxReplicas to 8.
apiVersion: cloud.streamnative.io/v1alpha1
kind: Function
metadata:
name: java-function-sample
namespace: default
spec:
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
forwardSourceMessageProperty: true
maxPendingAsyncRequests: 1000
replicas: 1
maxReplicas: 8
# Other function configs
Configure HPA with built-in metrics
Function Mesh supports autoscaling the number of Pods based on supported built-in metrics.
Note
If you specify multiple metrics for the HPA to scale up, the HPA controller evaluates each metric, and proposes a new scale based on that metric. The largest of the proposed scales will be used as the new scale.
This example shows how to auto-scale the number of Pods to 8 when 20% CPU is used.
Specify the CPU-based HPA metric under
pod.builtinAutoscalerin the Pulsar Functions CRD.apiVersion: cloud.streamnative.io/v1alpha1
kind: Function
metadata:
name: java-function-sample
namespace: default
spec:
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
forwardSourceMessageProperty: true
maxPendingAsyncRequests: 1000
replicas: 1
maxReplicas: 4 # --- [1]
logTopic: persistent://public/default/logging-function-logs
input:
topics:
- persistent://public/default/java-function-input-topic
typeClassName: java.lang.String
pod:
builtinAutoscaler: # --- [2]
- AverageUtilizationCPUPercent20
# Other function configs- [1]
maxReplicas: enables HPA when the value is greater than that of thereplicas. - [2]
builtinAutoscaler: configures the built-in HPA metrics.
- [1]
Apply the configurations.
kubectl apply -f path/to/function-sample.yaml
Configure HPA with custom metrics
Function Mesh supports automatically scaling up the number of Pods based on a custom HPA metric.
This example shows how to auto-scale the number of Pods if 45% CPU is used.
Specify the custom HPA metric under
pod.autoScalingMetricsin the Pulsar Functions CRD.apiVersion: cloud.streamnative.io/v1alpha1
kind: Function
metadata:
name: java-function-sample
namespace: default
spec:
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
forwardSourceMessageProperty: true
maxPendingAsyncRequests: 1000
replicas: 1
maxReplicas: 4 # --- [1]
logTopic: persistent://public/default/logging-function-logs
pod:
autoScalingMetrics: # --- [2]
- type: Resource
resource:
name: cpu # --- [3]
target:
type: Utilization
averageUtilization: 45 # --- [4]
# Other function configs- [1]
maxReplicas: enables autoscaling when the value is greater than that of thereplicas. - [2]
autoScalingMetrics: represents the custom autoscaling metrics. - [3]
name: defines the name of resources to be used. It can be set to the valuecpuormemory. - [4]
averageUtilization: defines the percentage of the resource usage.
- [1]
Apply the configurations.
kubectl apply -f path/to/function-sample.yaml
If a large number of resources are used suddenly, you can use the
autoScalingBehavior.scaleUp.stabilizationWindowSecondsoption to adjust the value of the stabilization window to tune performance.Specify the value of the stabilization window in the Pulsar Functions CRD.
apiVersion: cloud.streamnative.io/v1alpha1
kind: Function
metadata:
name: java-function-sample
namespace: default
spec:
minReplicas: 1
maxReplicas: 10
pod:
autoScalingMetrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
autoScalingBehavior:
scaleUp: # --- [1]
stabilizationWindowSeconds: 120 # --- [2]
policies: # --- [3]
- type: Percent # --- [4]
value: 100 # --- [5]
periodSeconds: 15 # --- [6]
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max # --- [7]- [1]
scaleUp: specifies the rules that are used to control scaling behavior while scaling up. - [2]
stabilizationWindowSeconds: indicates the amount of time the HPA controller should consider previous recommendations to prevent flapping of the number of replicas. - [3]
policies: a list of policies that regulate the amount of scaling. Each item has the following fields: - [4]
type: can be set to the valuePodsorPercent, which indicates the allowed changes in terms of absolute number of pods or percentage of current replicas. - [5]
periodSeconds: represents the amount of time in seconds that the rule should hold true for. - [6]
value: represents the value for the policy. - [7]
selectPolicy: can beMin,MaxorDisabledand specifies which value from the policies should be selected. By default, it is set toMaxvalue.
- [1]
Apply the configurations.
kubectl apply -f path/to/function-sample.yaml
VPA
Vertical scaling increases loads by assigning more resources (memory or CPU) to the Pods that are already running for the workload.
How it works
With Kubernetes Vertical Pod Autoscaler (VPA), Function Mesh supports automatically updating the resource requests and limits (memory or CPU) of Pods (Pulsar instances) that are required to run Pulsar functions, sources, and sinks based on analysis of historical resource utilization, amount of resources available in the cluster, and real-time events, such as OOMs.
A VPA deployment has three main components: VPA Recommender, VPA Updater, and VPA Admission Controller.
The VPA Recommender consumes utilization signals and OOM events for all Pods in the cluster from the Metrics server by
watching all Pods, calculating fresh recommended resources for them, and storing the recommendations in the VPA objects.
exposes a synchronous API that takes a Pod description and returns recommended resources.
The VPA Admission Controller controls all Pod creation requests. If a Pod is matched by any VPA object, the VPA Admission Controller overrides the resources of containers in the Pod with the recommendation provided by the VPA Recommender. If the VPA Recommender is not available, the VPA Admission Controller falls back to the recommendation cached in the VPA object.
The VPA Updater is responsible for updating Pods in real-time. If a Pod uses VPA in Auto mode, the VPA Updater updates the Pod with the recommended resources.
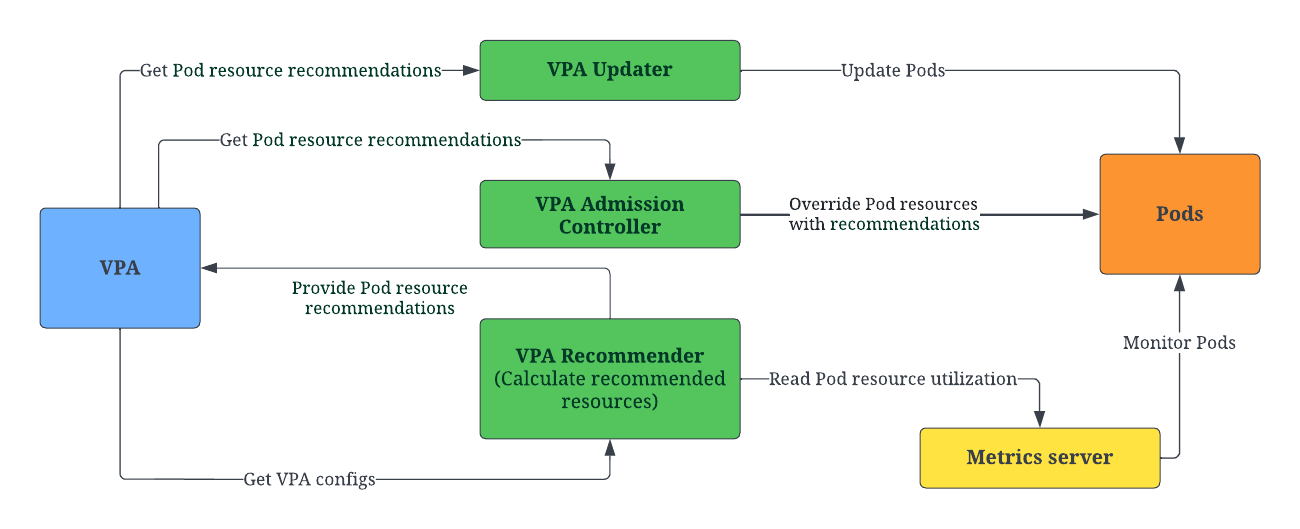
Note
VPA won't work with HPA. Therefore, do not enable both of them at the same time.
Limitations
There are some limitations to VPA. For details, see known limitations.
Examples
This section provides some examples about VPA.
Prerequisites
Deploy the Metrics server in the cluster. The Metrics server provides metrics through the Metrics API that is used by VPA to collect metrics. For details about how to deploy the Metrics server, see the Metrics server documentation.
Enable VPA in the Kubernetes cluster. Currently, VPA has not been integrated into Kubernetes. For details about how to enable VPA in the Kubernetes cluster, see related documentation.
Enable VPA based on resource limits
This example shows how to update Pod resources with the maximum and minimum bound automatically.
apiVersion: compute.functionmesh.io/v1alpha1
kind: Function
metadata:
name: function-sample-vpa
namespace: default
spec:
image: streamnative/pulsar-functions-java-sample:2.9.2.23
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
forwardSourceMessageProperty: true
maxPendingAsyncRequests: 1000
replicas: 2 # --- [1]
pod:
vpa:
updatePolicy:
updateMode: "Auto" # --- [2]
resourcePolicy:
containerPolicies:
- containerName: "*" # --- [3]
minAllowed: # --- [4]
cpu: 200m
memory: 100Mi
maxAllowed: # --- [5]
cpu: 1
memory: 1000Mi
# Other function configs
- [1]
replicas: it should be equal to or greater than the value of theminReplicas. By default, it is set to 2. Therefore, VPA can update resources for the Pods and ensure that at least there are live Pods during the update process. You can modify the minimal value by setting thepod.vpa.updatePolicy.minReplicasoption. - [2]
updateMode: define the behavior of the VPA Updater.AutoorRecreate: the VPA Updater recreates Pods when the resource recommendation is changed.Initial: the VPA Updater only assigns resources on Pod creation.Off: the VPA Updater does nothing to Pods but just saves the recommended resources in the VPA object.
- [3]
containerName: specify different resource policies for different containers. The asterisk symbol (*) means that you can specify resource policies for all containers. - [4]
minAllowed: the minimum value of recommended resources. - [5]
maxAllowed: the maximum value of recommended resources.
Enable VPA based on resource requests
Requests define the minimum amount of resources that containers need. This example shows how to update Pods based on resource requests.
apiVersion: compute.functionmesh.io/v1alpha1
kind: Function
metadata:
name: function-sample-vpa
namespace: default
spec:
image: streamnative/pulsar-functions-java-sample:2.9.2.23
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
forwardSourceMessageProperty: true
maxPendingAsyncRequests: 1000
replicas: 2
pod:
vpa:
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: "*"
controlledValues: "RequestsOnly" # --- [1]
# Other function configs
- [1]
controlledValues: the VPA Recommender controls the resource requests. To control both the requests and limits, you can set it toRequestsAndLimits
Enable VPA based on CPU resources
This example shows how to update Pods based on CPU resource requests.
apiVersion: compute.functionmesh.io/v1alpha1
kind: Function
metadata:
name: function-sample-vpa
namespace: default
spec:
image: streamnative/pulsar-functions-java-sample:2.9.2.23
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
forwardSourceMessageProperty: true
maxPendingAsyncRequests: 1000
replicas: 2
pod:
vpa:
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: "*"
controlledResources: ["cpu"] # --- [1]
# Other function configs
- [1]
controlledResources: the VPA Recommender controls the CPU resources. To control memories, you can add memory to the array.