What is Function Mesh?
Function Mesh is a serverless framework purpose-built for stream processing applications. It brings powerful event-streaming capabilities to your applications by orchestrating multiple Pulsar Functions and Pulsar IO connectors for complex stream processing jobs.
Concepts
Function Mesh enables you to build event streaming applications leveraging your familiarity with Apache Pulsar and mordern stream processing technologies. Three concepts are foundational to build an application: streams, functions, and connectors.
Stream
A stream is a partitioned, immutable, append-only sequence for events that represents a series of historical facts. For example, the events of a stream could model a sequence of financial transactions, like "Jack sent $100 to Alice", followed by "Alice sent $50 to Bob".
A stream is used for connecting functions and connectors.
Topics in a messaging system are usually used for presenting the streams. The streams in Function Mesh are implemented by using topics in Apache Pulsar.
Figure 1 illustrates a stream.

Figure 1. A stream that connects a function and a connector
Function
A function is a lightweight event processor that consumes messages from one or more input streams, applies a user-supplied processing logic to one or multiple messages, and produces the results of the processing logic to another stream.
The functions in Function Mesh are implemented based on Pulsar Functions.
Figure 2 illustrates a function.

Figure 2. A function that consumes messages from one or more input streams and produces the results to another output stream
Connector
A connector is a processor that ingresses or egresses events from and to streams. There are two types of connectors in Function Mesh:
- Source Connector (aka Source): a processor that ingests events from an external data system into a stream.
- Sink Connector (aka Sink): a processor that egresses events from streams to an external data system.
The connectors in Function Mesh are implemented based on Pulsar IO connectors. The available Pulsar I/O connectors can be found at StreamNative Hub.
Figure 3 illustrates a source connector.

Figure 3. A source connector that consumes change events from MySQL and ingests them to an output streams
Figure 4 illustartes a sink connector.

Figure 4. A sink connector that egresses events from streams to ElasticSearch
FunctionMesh
A FunctionMesh (aka Mesh) is a collection of functions and connectors connected by streams that are orchestrated together for achieving powerful stream processing logics.
All the functions and connectors in a FunctionMesh share the same lifecycle. They are started when a FunctionMesh is created and terminated when the mesh is destroyed. All the event processors are long running processes. They are auto-scaled based on the workload by the Function Mesh controller.
A FunctionMesh can be either a Directed Acyclic Graph (DAG) or a cyclic graph of functions and/or connectors connected with streams. Figure 5 illustrates a FunctionMesh of a Debezium source connector, an enrichement function, and an Elastic sink connector.
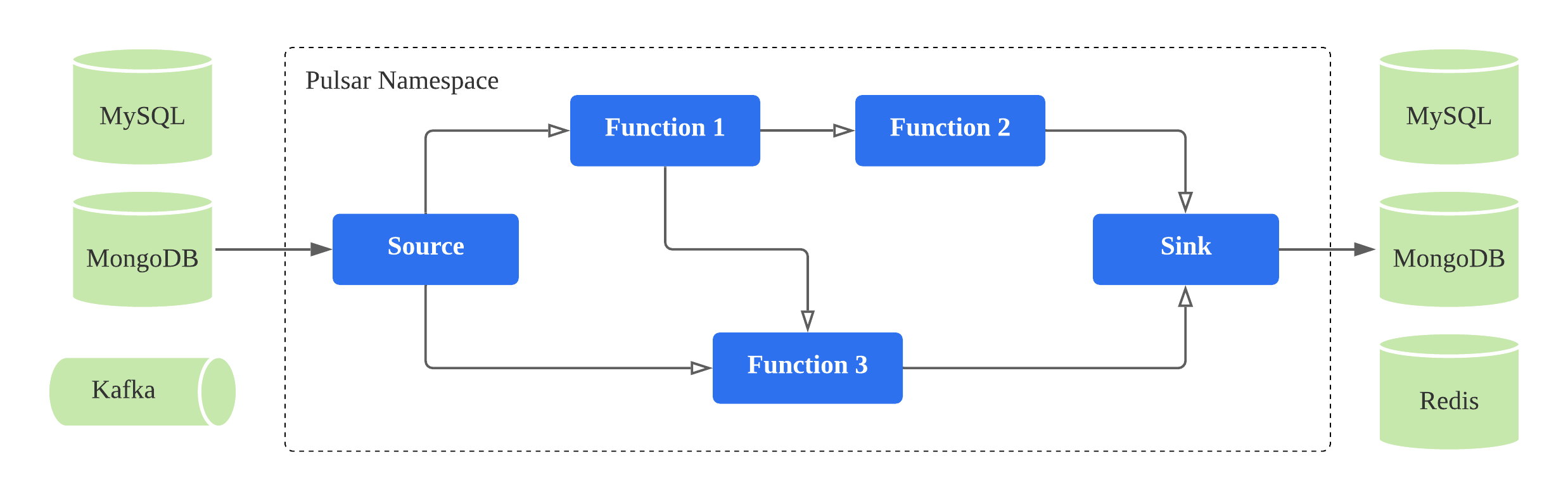
Figure 5. A FunctionMesh is a collection of functions and/or connectors connected with streams
API
Function Mesh APIs build on existing Kubernetes APIs, so that Function Mesh resources are compatible with other Kubernetes-native resources, and can be managed by cluster administrators using existing Kubernetes tools.
Common languages and frameworks that include Kubernetes-friendly tooling work smoothly with Function Mesh to reduce the time spent solving common deployment issues.
The foundational concepts described above are delivered as Kubernetes Custom Resource Definitions (CRDs), which can be configured by a cluster administrator for developing event streaming applications.
The available Function Mesh CRDs are:
- Function: The
Functionresource automatically manages the whole lifecycle of a Pulsar Function. - Source: The
Sourceresource automatically manages the whole lifecycle of a Pulsar Source connector. - Sink: The
Sinkresource automatically manages the whole lifecycle of a Pulsar Sink connector. - FunctionMesh: The
FunctionMeshresource automatically manages the whole lifecycle of your event streaming application. It controls the creation of other objects to ensure that the functions and connectors defined in your mesh are running and they are connected via the defined streams.
A typical user workflow is illustrated in Figure 6.
- A user creates a CRD yaml to define the function, connector, or mesh to run.
- The user submits the CRD using the Kubernetes tooling.
- The Function Mesh controller watches the CRD and creates Kubernetes resources to run the defined function, connector, or mesh.
The benefit of this approach is both the function metadata and function running state are directly stored and managed by Kubernetes to avoid the inconsistency problem that was seen using Pulsar's existing Kubernetes scheduler. See Why Function Mesh for more details.
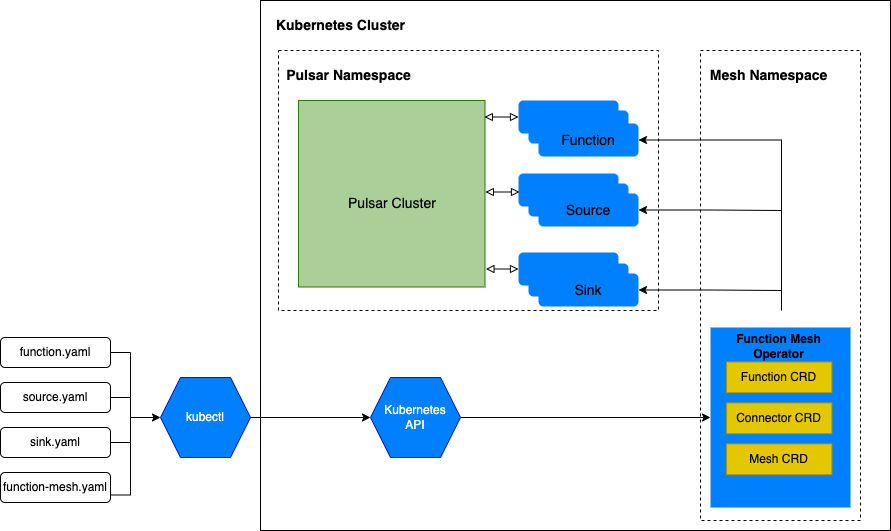
Figure 6. The Function Mesh user workflow
Architecture
Figure 7 illustrates the overall architecture of Function Mesh. Function Mesh consists of two components.
- Controller: A Kubernetes operator that watches Function Mesh CRDs and creates Kubernetes resources (i.e. StatefulSet) to run functions, connectors, and meshes on Kubernetes.
- Runner: A Function Runner that invokes functions and connectors logic when receiving events from input streams and produces the results to output streams. It is currently implemented using Pulsar Functions runner.
When a user creates a Function Mesh CRD, the controller receives the submitted CRD from Kubernetes API server. The controller processes the CRD and generates the corresponding Kubernetes resources. For example, when the controller processes the Function CRD, it creates a StatefulSet to run the function. Each pod of this function StatefulSet will launch a Runner to invoke the function logic.
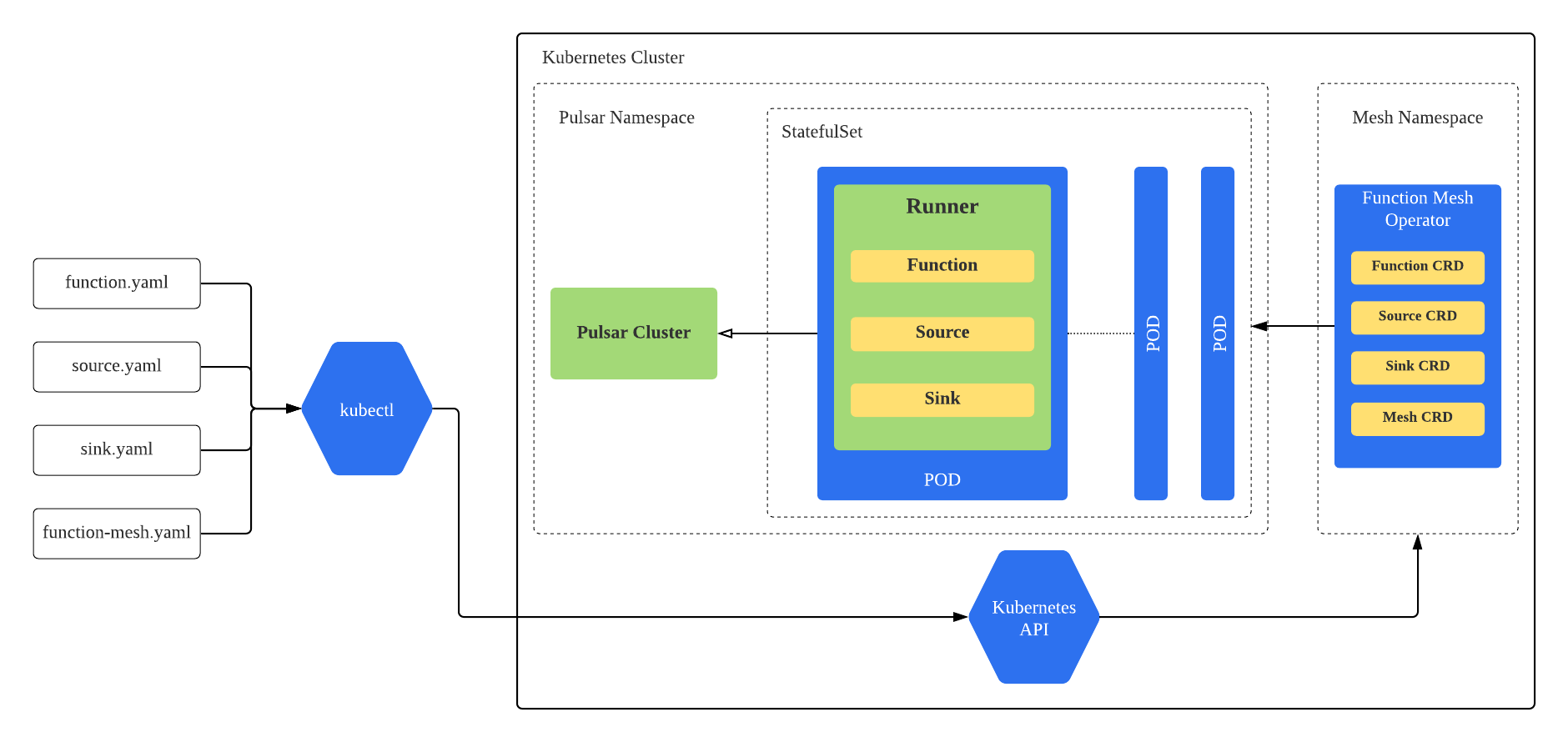
Figure 7. The Function Mesh architecture
Features
- Be easily deployed directly on Kubernetes clusters, including Minikube and Kind, without special dependencies.
- Use CustomResourceDefinitions (CRD) to define Functions, source, sink, and Mesh. Using CRD makes Function Mesh naturally integrate with the Kubernetes ecosystem.
- Integrate with Kubernetes secrets seamlessly to read secrets directly. This helps improve the overall security for the Pulsar Functions.
- Leverage the Kubernetes's auto-scaler to auto-scale instances for functions based on the CPU and memory usage.
- Utilize the full power scheduling capability provided by Kubernetes. Therefore, you do not need to write any customized codes to communicate with the Kubernetes API server.
- Allow one function to talk to multiple different Pulsar clusters, which are defined as config maps.
- Support the function registry for function package management. The function package can be reused by different functions.
Documentation
- Overview
- Installation
- Functions
- Pulsar Functions overview
- Pulsar Functions CRD configurations
- Package Pulsar Functions
- Run Pulsar Functions
- Monitor Pulsar Functions
- Produce function logs
- Debug Pulsar Functions
- Connectors
- Meshes
- Scaling
- Migration
- Reference
- Releases
- Release notes v0.1.4
- Release notes v0.1.5
- Release notes v0.1.6
- Release notes v0.1.7
- Release notes v0.1.8
- Release notes v0.1.11
- Release notes v0.2.0
- Release notes v0.3.0
- Release notes v0.4.0
- Release notes v0.5.0
- Release notes v0.6.0
- Release notes v0.7.0
- Release notes v0.8.0
- Release notes v0.9.0
- Release notes v0.10.0